今日头条公开推荐算法原理:用户、环境、资讯如何匹配?资深架构师曹欢欢详解

1月11日,在北京总部,关于咨询算法和建议的“使算法开放且透明”的共享会议正在进行中。 观察到,包括BAT在内的许多技术公司的算法工程师和产品经理在内的100多人参加了现场讨论。中国科学技术大学的高级算法建筑师和科学技术的高级算法尚豪安博士在当场介绍了当场推荐算法的原理。

Cao 说,信息建议系统基本上需要解决用户,环境和信息的匹配。为了达到这种效果,其算法推荐系统进入三个维变量:
基于这三个维度,的推荐模型估算了此内容在这种情况下是否适合此用户。
为了取得良好的结果,需要解决这四种类型的特征:
但是,Cao 表示,可以对单击率,阅读时间,喜欢,评论和转发都可以进行量化,但是大规模推荐系统具有大量用户,并且不能通过指标对其进行充分评估。引入数据以外的其他元素也很重要。可以完成某些算法,而某些算法不能完成或做得不好,这需要内容干预。
简而言之,没有适用于所有推荐方案的通用模型体系结构。 仍然需要一个非常灵活的算法实验平台。该算法不起作用。立即尝试另一种算法,这实际上是各种算法的复杂组合。根据的说法,Xigua视频,火山短视频,简短视频和问答都使用的推荐系统,但是对于每个系统,架构都是不同的,您需要继续尝试。
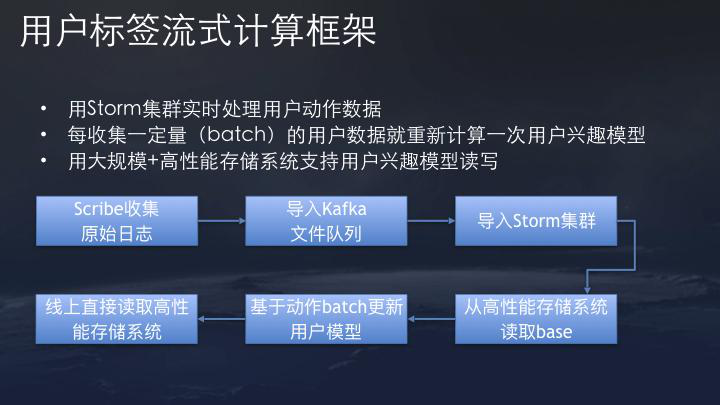
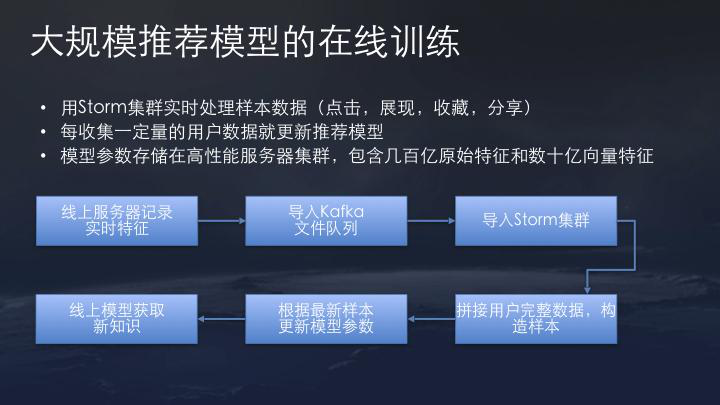
根据上述重复培训建议的需求,在全球范围内拥有相对较大的在线培训建议模型,其中包括数百亿个功能和数十亿个矢量功能。
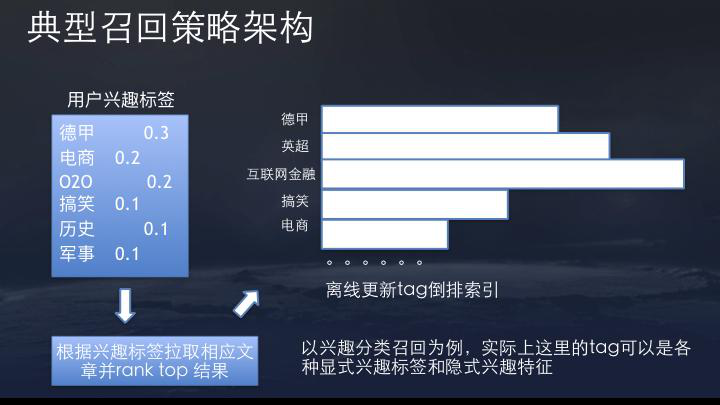
但是,完全依赖模型建议的成本太高了。因此,还具有一个召回模型,可以简化策略 - 基于召回策略,它将大规模且不可预测的内容库变成一个相对较小且功能较小的内容库,然后进入推荐模型。这有效地平衡了计算成本和效果。
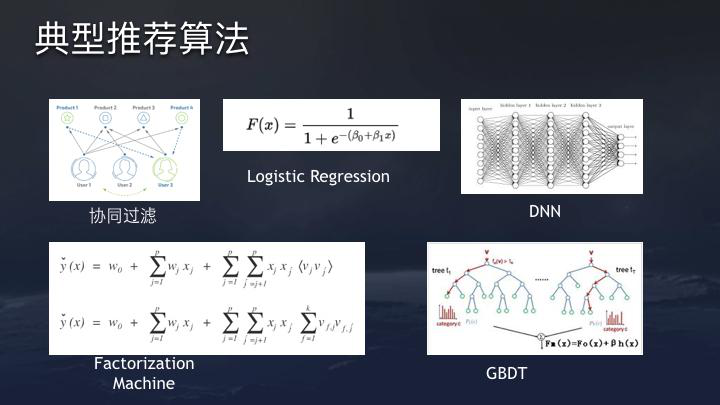
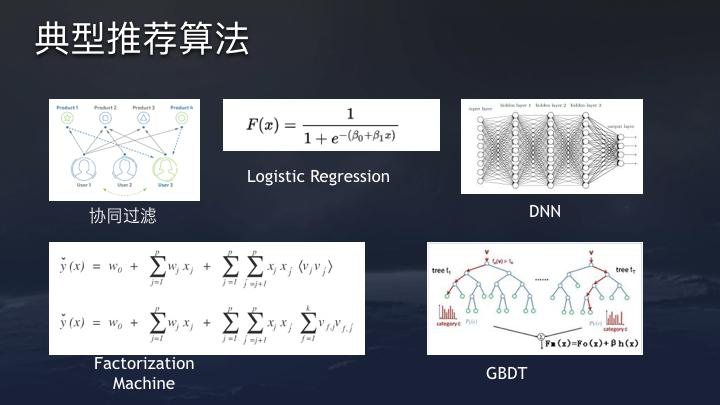
Cao 说,在工作的头三年,我从用户的反馈中收到的最大问题是 - “为什么您总是让我重复?”
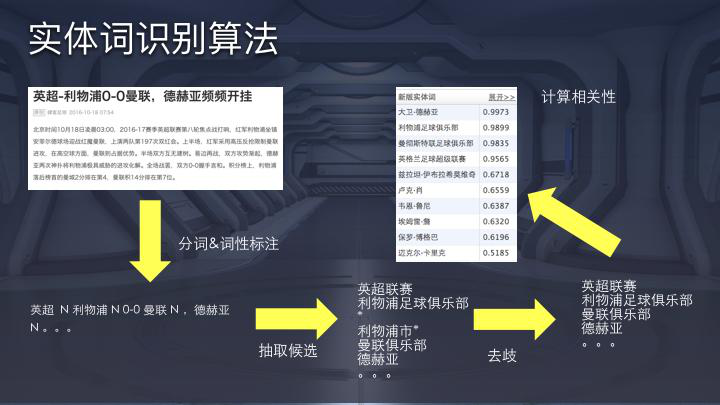
Cao 解释说,每个人都有不同的重复定义。有人昨天看到了一篇有关巴塞罗那的文章,今天还有另外两篇文章,可能会感到烦恼。但是,对于像巴塞罗那粉丝这样的沉重粉丝,他们可能希望阅读所有报道。为了解决此问题,您需要准确提取文本功能,例如哪些文章说同一件事,哪些文章基本相同。建议的文本功能的独特价值是,如果没有文本功能,建议引擎就无法正常工作。同时,文本特征的粒度越高,冷启动能力越强。

语义标签的影响是检查公司的NLP(自然语言处理)。
重要的产品功能(例如渠道和兴趣表达)需要明确定义且易于理解的文本标签系统。当隐性语义功能已经可以帮助推荐和制作良好的语义标签时,仍然有必要制作良好的语义标签。
除了用户的天然标签外,建议还需要考虑许多复杂的情况:
实际上,有许多因素影响推荐效应。需要一个完整的评估系统。您不仅要查看一个指标,例如点击率,保留率,收入或互动。您需要查看对许多指标的全面评估:考虑到短期指标和长期指标,同时考虑到用户指标和生态指标,注意协同作用的影响,有时需要彻底的统计隔离。
那么,所有这些指标都可以合成独特的公式吗? “我们已经努力探索了几年,但我们还没有做到。”
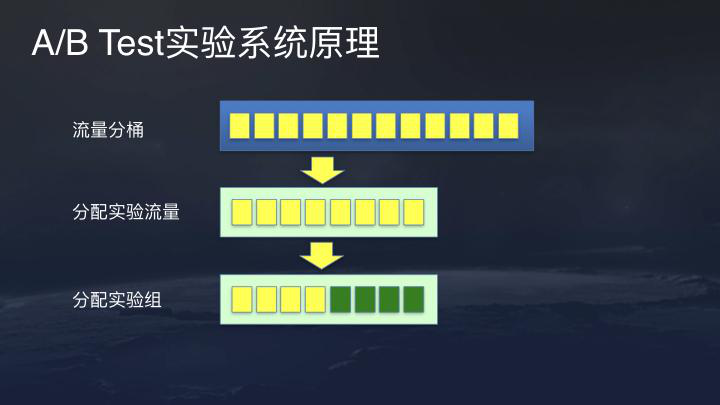
此外,Cao 说,许多公司的当前算法不佳,这不是人类的问题,而是实验平台的问题。例如,每次A/B测试的数据都是错误的,并且不能将其放在线上,最终将破坏此问题。一个强大的实验平台每天可以在线实现数百个实验,有效地管理和分配实验流量,降低实验分析成本并提高算法迭代效率。
根据的说法,现在有一个合理的内容安全机制。除了手动审查团队外,它还具有技术识别,包括风险内容识别技术,黄色识别模型,这些模型建立了数以百万计的图片,庸俗模型和具有超过一百万个样本库的侮辱模型的样本,以及一般的低质量内容识别技术,CAO 强调。
